
Center for Information Systems & Data Science
Research: Foundations
Optimization plays a significant role in most sectors of engineering and economics. In airline planning, finance, engineering design, biological systems, and other fields, optimization plays a critical role. We strive to maximize important parameters in these situations, such as maximizing profitability and efficiency, or minimizing costs and energy use. As the resources and time are always limited, efficiency becomes even more important.
Recent advancements in data science and computational resources and algorithms have made a significant impact in the field of optimization. Today, large-scale optimization problems can be efficiently solved, while no one could expect them to be addressed ten years ago. New algorithms and discoveries, in addition to the technological advancements, have made significant improvements in the field of optimization.
The Sharif Data Science Center's research focuses on large-scale discrete and continuous optimization, both theoretically and practically. The study areas include stochastic optimization, robust optimization, combinatorial optimization and convex and non-convex optimization.
In addition to the above topics, the area of Quantum Computation has been advancing in top research centers such as Microsoft and Google and large investments have been allocated to this field. In this regards, the Sharif Data Science Research Center has special interest in this field and we plan to cooperate closely with the Quantum group of the Institute to establish a leading edge multi-disciplinary path in this area. The figure below shows some possible joint topics of interest for these two centers.
Recent advancements in data science and computational resources and algorithms have made a significant impact in the field of optimization. Today, large-scale optimization problems can be efficiently solved, while no one could expect them to be addressed ten years ago. New algorithms and discoveries, in addition to the technological advancements, have made significant improvements in the field of optimization.
The Sharif Data Science Center's research focuses on large-scale discrete and continuous optimization, both theoretically and practically. The study areas include stochastic optimization, robust optimization, combinatorial optimization and convex and non-convex optimization.
In addition to the above topics, the area of Quantum Computation has been advancing in top research centers such as Microsoft and Google and large investments have been allocated to this field. In this regards, the Sharif Data Science Research Center has special interest in this field and we plan to cooperate closely with the Quantum group of the Institute to establish a leading edge multi-disciplinary path in this area. The figure below shows some possible joint topics of interest for these two centers.
Robust and Stochastic Optimization
Robust optimization deals with uncertainty in the data of the optimization problems. The goal is to make a decision that is feasible in respect to constraints. Randomness can enter the problem in two ways: through the cost function or the constraint set. Also, stochastic optimization refers to a collection of methods for minimizing or maximizing an objective function when uncertainty is present. Both topics are becoming essential tools for data scientists over the last years.
Combinatorial Optimization
Many real-world problems are naturally represented as combinatorial optimization problems, that is, problems of finding the best solution(s) from a finite set. Various methods, such as integer programming, fixed-parameter tractable and exact algorithms, approximation algorithms, and combinatorial algorithms, have been developed to overcome such challenges. These methods can be used to solve problems in a variety of fields, including bioinformatics, geometry, scheduling and others.
Optimization (convex and non-convex) for ML and (deep) neural networks
Convex optimization involves a function in which there is only one local optimum, and that is the global maximum or minimum. On the other hand, neural networks have plenty of local optimal points. Thus, finding the global optimal or even a suitable local optimal is difficult. Due to the increasing attention of neural networks to various issues, non-convex optimization is becoming very practical, helping us train our networks. For example, using a reasonable learning rate and different methods to escape from local optima can help solve this problem (Ref).
Today, there is almost no primary industry that has not been affected by artificial intelligence. Cancer and disease diagnostics, weather forecasting, self-driving cars, and voice assistants are just a few examples of the growing applications in this field.
Artificial intelligence is the core of machine learning. It helps computers process large amounts of data and use its information to make optimal decisions in a short amount of time. Nowadays, deep learning methods with big data and wide range of architectures have been developed in various applications. Recently, advances in data collection and processing technology have also increased interest in this field.
Sharif Data Science Center explores the foundations of machine learning and decision-making systems. The Center's research covers various theoretical and practical topics. ML theory, optimization, statistical learning and inference, AI algorithms, deep learning, reinforcement learning, computer vision, and natural language processing are among the topics in this area.
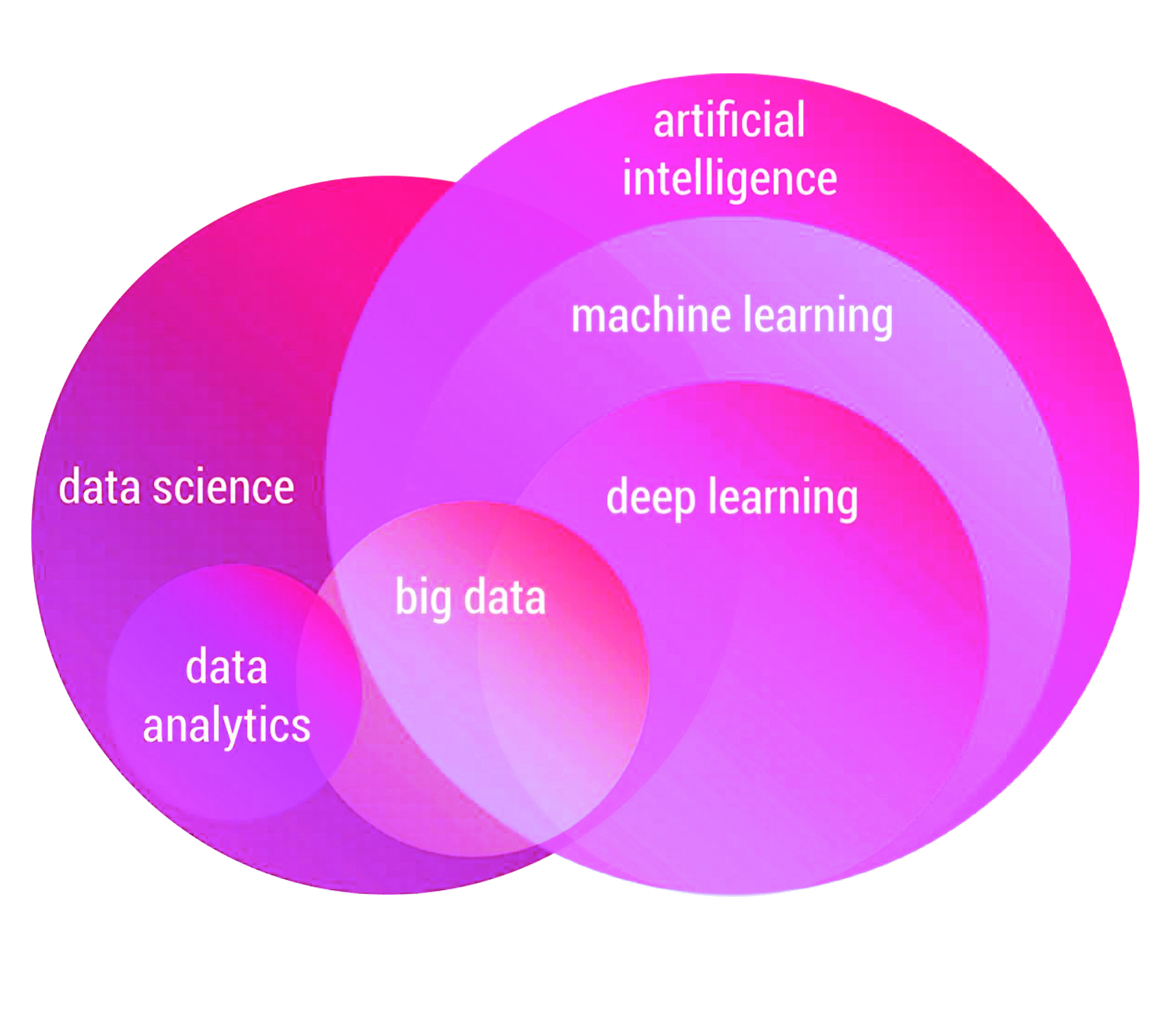
Artificial intelligence is the core of machine learning. It helps computers process large amounts of data and use its information to make optimal decisions in a short amount of time. Nowadays, deep learning methods with big data and wide range of architectures have been developed in various applications. Recently, advances in data collection and processing technology have also increased interest in this field.
Sharif Data Science Center explores the foundations of machine learning and decision-making systems. The Center's research covers various theoretical and practical topics. ML theory, optimization, statistical learning and inference, AI algorithms, deep learning, reinforcement learning, computer vision, and natural language processing are among the topics in this area.
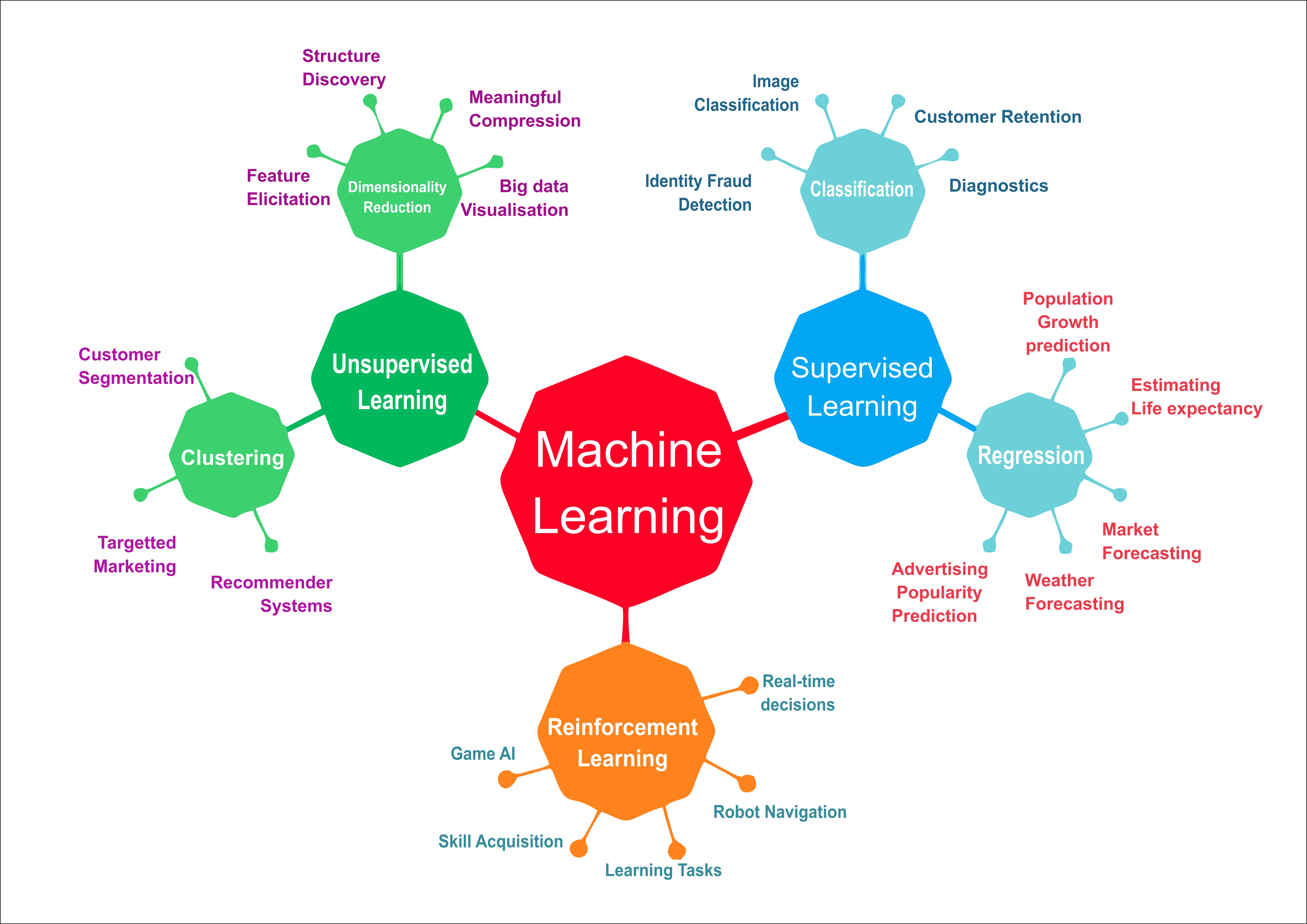
Deep Learning
Deep learning is a method of machine learning based on neural networks. These networks allow learning from large amounts of data. Deep learning methods have achieved very high accuracy in various applications by increasing the number of layers of neural networks and adopting proper architectures.
Reinforcement Learning
Reinforcement learning is another branch of machine learning in which an AI agent learns how to behave in an environment by taking actions and observing the results. The agent is trained in an interactive environment with trial and error and feedback on his actions. Robotics and computer games are some of traditional RL's real-world applications, but in recent years RL has found applications in much wider areas.

Natural Language Processing
Natural Language Processing (NLP) is the process of understanding human language by a machine. Language can be spoken or written, and the machine must recognize, understand, and generate it. NLP has its roots in linguistics, but in the late twentieth century, with the introduction of statistical methods and increasing the computing power of processors, a revolution took place in this field and became one of the most important branches of artificial intelligence. Subsequently, machine and neural network learning methods became popular due to their high accuracy in natural language processing, achieving similar results to humans. Some of the numerous NLP real-world applications are voice assistants, chatbots, grammar correction, machine translation, text classification and summarization, sentiment analysis, and market analytics.
Computer Vision
Computer vision is a field of artificial intelligence that focuses on extracting meaningful information from digital images and movies. The machine can make a decision or guide us based on such information. For example, a trained product inspection system can analyze thousands of products per minute much faster than humans. Computer vision has applications in various industries, from energy and utilities to automotive manufacturing. Image classification, object recognition, object tracking, and content-based image retrieval are major topics in this area.
Recent advances in developing optimal algorithms with practical and distinguished implementations are made possible thanks to the insightful interplay of ideas from information theory, learning theory, statistics, probability, and theoretical computer science, leading to the advancement of universal schemes.
Information-theoretic ideas are applicable to a wide range of problems, spanning machine learning, statistics, theoretical computer science, online learning, bandits, operations research, etc. Information theory provides insightful guidelines for choosing and developing contextually appropriate tools for different problems.
Information theory was initially developed to seek for some solutions to the fundamental problems in the theory of communications; however, the connection of information theory to statistics and inference has made a major breakthrough in various recent applications, including machine learning, statistical learning, and causal inference.
Information-theoretic methods are capable of providing insights, together with efficient algorithms, for a diversified range of inferential tasks. Moreover, the basic quantitative measures introduced by information theory---including cross entropy, relative entropy, and their generalizations to divergence measures such as f-divergences---are the key material towards proposing and analyzing optimal algorithms in a variety of hot topics in mathematical statistics, learning and probability theory.
In addition to providing explicit solutions to real problems, information theory also plays an important role to understand and address “what is impossible”. Impossibility results, which are obtained from characterizing information-theoretic “fundamental limits,” help recognize unrealistic scientific goals and find bottlenecks. Optimality guarantees could also be achieved for constructive procedures.
Information-theoretic methods play their roles in different fields of data science:
Information-theoretic ideas are applicable to a wide range of problems, spanning machine learning, statistics, theoretical computer science, online learning, bandits, operations research, etc. Information theory provides insightful guidelines for choosing and developing contextually appropriate tools for different problems.
Information theory was initially developed to seek for some solutions to the fundamental problems in the theory of communications; however, the connection of information theory to statistics and inference has made a major breakthrough in various recent applications, including machine learning, statistical learning, and causal inference.
Information-theoretic methods are capable of providing insights, together with efficient algorithms, for a diversified range of inferential tasks. Moreover, the basic quantitative measures introduced by information theory---including cross entropy, relative entropy, and their generalizations to divergence measures such as f-divergences---are the key material towards proposing and analyzing optimal algorithms in a variety of hot topics in mathematical statistics, learning and probability theory.
In addition to providing explicit solutions to real problems, information theory also plays an important role to understand and address “what is impossible”. Impossibility results, which are obtained from characterizing information-theoretic “fundamental limits,” help recognize unrealistic scientific goals and find bottlenecks. Optimality guarantees could also be achieved for constructive procedures.
Information-theoretic methods play their roles in different fields of data science:
- What is the best representation for a message within a communication setup?
- How much computation and memory does one need to learn the distribution of the data?
- What is the smallest error achievable in a classification task?
- How many iterations does one need to reach the optimal solution for optimization problems?
Different topics in the context of Information Theory:
- Mathematical statistics: optimal error probabilities in hypothesis testing, rates of convergence for estimation problems, etc.
- Probability: empirical process theory and concentration of measure.
- Game theory
- Learning Theory
- High Dimensional Statistics
- Stochastic optimization and approximation
- Information-theoretical understanding and theoretical issues of deep learning and generative models
- Quantum Information and Computation
- Bioinformatics
- Latency-Sensitive Communication (Theory and practice)
- Finite Block Length Information Theory
- Codes for Clouds:
- Coded computation
- Private information retrieval
- Distributed storage
- Blockchains and Distributed Computing
- Computational and Synthetic Biology

- Private information retrieval
- Distributed storage
- Blockchains and Distributed Computing
- Computational and Synthetic Biology
According to the McKinsey Global Institute, the demand for data visualization experts in the United States could reach two to four million by 2026.
Data visualization reveals subtleties, insights, and structure in data that might otherwise go unnoticed, providing us with a powerful perspective. To make data more understandable and usable for end users, information must be transformed into appealing – and valuable – graphs. Furthermore, data scientists need good visual representations of datasets or models to discover trends or outliers during the model building process.
Businesses design data models to match their needs. Rules and requirements are created ahead of time based on feedback from business stakeholders, so they may be incorporated into the design of a new system or changed throughout the iteration of an existing one. Data models are dynamic documents that change as the needs of the business change. They play a critical role in both company operations and the development of IT architecture and strategy. Data models can help vendors, partners, and/or industry peers.
Large volumes of data were amassing during the early years of the big data movement, and organizations needed a way to get a quick and easy overview of their data. When a data scientist constructs advanced predictive analytics or machine learning (ML) algorithms, it is vital to show the results in a way that one can maintain track of the results and make sure the models are performing correctly. This is because visual representations of complex algorithms are often easier to comprehend than numerical results. Visualization also plays a pivotal role in advanced analytics. Thanks to the fact that visualizations of complex algorithms are much easier to interpret than numerical outputs, data scientist who contribute to advanced predictive analytics or ML algorithms need to visualize the outputs to monitor results and make sure that the considered models are performing as intended.

Data visualization reveals subtleties, insights, and structure in data that might otherwise go unnoticed, providing us with a powerful perspective. To make data more understandable and usable for end users, information must be transformed into appealing – and valuable – graphs. Furthermore, data scientists need good visual representations of datasets or models to discover trends or outliers during the model building process.
Businesses design data models to match their needs. Rules and requirements are created ahead of time based on feedback from business stakeholders, so they may be incorporated into the design of a new system or changed throughout the iteration of an existing one. Data models are dynamic documents that change as the needs of the business change. They play a critical role in both company operations and the development of IT architecture and strategy. Data models can help vendors, partners, and/or industry peers.
Large volumes of data were amassing during the early years of the big data movement, and organizations needed a way to get a quick and easy overview of their data. When a data scientist constructs advanced predictive analytics or machine learning (ML) algorithms, it is vital to show the results in a way that one can maintain track of the results and make sure the models are performing correctly. This is because visual representations of complex algorithms are often easier to comprehend than numerical results. Visualization also plays a pivotal role in advanced analytics. Thanks to the fact that visualizations of complex algorithms are much easier to interpret than numerical outputs, data scientist who contribute to advanced predictive analytics or ML algorithms need to visualize the outputs to monitor results and make sure that the considered models are performing as intended.
Networks and Graphs Theory
Complex network systems are the focus of network science. Computer networks, telecommunications, biology, social science, and economics are a few examples of such systems. In this regard, graph theory and network science are two closely related subjects that have recently found extensive application in the industry. Current concerns in network research include the analysis of social networks, transportation networks, gene regulatory networks, and knowledge networks. The network's intuitive and adaptable character makes it an effective tool for describing complex real-world systems. Graph and network theories are regarded the cornerstone of network research because they allow us to model these systems using graphs. In addition to graph theory, statistical and probabilistic methods, as well as data mining, are commonly employed in this area to address key challenges.

Security and privacy concerns play a pivotal role in the future world of interconnected intelligence. Protecting the privacy of users’ data on social networks or mobile phones, the identity theft within online transactions, and unauthorized access to the on-board chips of autonomous connected cars are some of the critically important challenges that directly affect clients in the context of services offered by data science and computer science-based technologies.
The everlasting race between adversarial attackers and the developers of defense mechanisms has made the data communications and computer networks vulnerable to privacy and security risks.
Cryptography and security algorithms were conventionally developed to focus on specific solutions for the applications of banking or communications. Recently, as a result of the amazing advances made in the areas of data science and computer science, a wide range of applications and systems require ubiquitous security and privacy guarantees. Examples include, but not limited to, connected cars, digital healthcare services, smart factories and smart buildings.
In order to bring end-to-end security and resiliency for the future interconnected intelligence, interdisciplinary approaches are required to combine cutting-edge foundational research with innovative hands-on applications in the areas of security and privacy for data science. Besides, leveraging the ubiquitous algorithms of artificial intelligence (AI) and machine learning (ML) helps improve the systems’ performance in terms of security and privacy.
Topics of interest:
The everlasting race between adversarial attackers and the developers of defense mechanisms has made the data communications and computer networks vulnerable to privacy and security risks.
Cryptography and security algorithms were conventionally developed to focus on specific solutions for the applications of banking or communications. Recently, as a result of the amazing advances made in the areas of data science and computer science, a wide range of applications and systems require ubiquitous security and privacy guarantees. Examples include, but not limited to, connected cars, digital healthcare services, smart factories and smart buildings.
In order to bring end-to-end security and resiliency for the future interconnected intelligence, interdisciplinary approaches are required to combine cutting-edge foundational research with innovative hands-on applications in the areas of security and privacy for data science. Besides, leveraging the ubiquitous algorithms of artificial intelligence (AI) and machine learning (ML) helps improve the systems’ performance in terms of security and privacy.
Topics of interest:
- Secure Mobile and Autonomous Systems
- Security and privacy in edge computing
- Security and privacy of networked systems and future internet (botnets, DDoS prevention, detection, investigation, and response
- Empirical and Behavioral Security
- Reliable Security Guarantees and Formal Methods
- Responsible Computing: Data Ethics, Web & Information Retrieval, Social Computing & Society.
- Verifiable computing and trustworthy processing
- Secure programming languages and compilation
- Hardware (Embedded) security
- Cryptocurrencies and Smart Contracts: Secure, and privacy-preserving solutions for modern cryptocurrencies
- Adversarial Attacks: Detection and Defense mechanisms
- Trustworthy Machine Learning:
- Robustness
- Security and Privacy
- Safety
- Fairness
- Accountability
- Causality
- Transparency
- Interpretability
- Governance and inclusion, etc.
- Security and Privacy
- Safety
- Fairness
- Accountability
- Causality
- Transparency
- Interpretability
- Governance and inclusion, etc.
- Synthetic Data Generation: Quality, Privacy, Bias
We need security and privacy solutions that work well in practice. To this end, it is required to draw insights from empirical and behavioral data. Therefore, security and privacy guarantee mechanisms for real-world applications that are capable of keeping pace with the continuing growth of IT infrastructures are needed to provide empirical methods for dealing with heterogeneous datasets on hand.